Recently, an idea to create GPU accelerated rendering of vector images occurred to me. These images contain not the color data itself, but the information about contours that form the final image. This vector image can be scaled without loss of detail.
Usually to render text on GPU, people use textures with glyph images in them. If you want to draw large scale symbols, you will have to increase the size of the image or scale the small one using bilinear or point filtering. I realized that it would be interesting to implement text rendering using vector fonts. Shader model 2.0 has some limitations, so I decided that I would support only black and white fonts.
To implement this I had to write a small tool that saves the information about the glyph outline (obtained using GetGlyphOutline function from WinAPI) into a texture. I also developed a software rendering prototype for testing.
GetGlyphOutline returns different representation of data for different parts of a glyph. If the part of the contour contains only straight lines, the list of points is returned. But for curved parts this function returns quadratic spline data. I decided to transform them into several straight lines, so the output data will be uniform. I found the equations in MSDN.

At first, I didn’t know how to determine if the given point is placed inside or outside a contour. Solution came shortly after: we will take line segment starting from arbitrary position (x;y) and ending at (+inf;y), and we will find number of intersections between line segment and glyph contour. Is the number is odd, the point is inside the outline and thus black.
But it is not so simple. You can’t just put the list of all segments into a texture and force GPU to make hundreds (or even more) texture samples for every fragment. At first, I wanted to write only single line equation into one texel which it crosses. But in that case the resolution of final texture will become too large, to make all small details distinguishable. The solution for the problem is to break glyph contour into small blocks with a limited number of line segments inside single one:
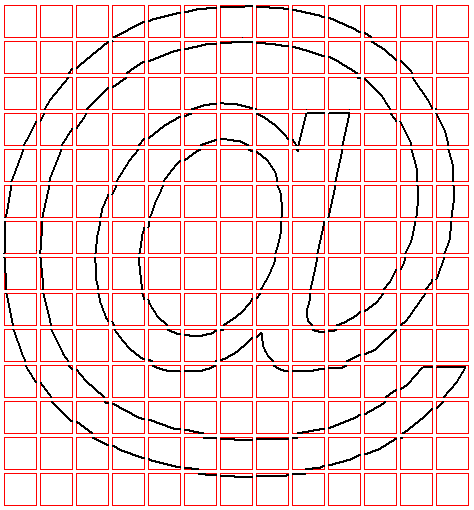
Line segment intersections will be done separately for every block. But if you divide outline like it is shown on the image above, you won’t get anywhere far from this:

For example, for the block in the center of the first row there isn’t a single intersection found at any position, the number of intersections is zero and the decision is made that they all are outside the outline. The situation is fixed by adding additional line segments at the right side of the block for the regions that are originally inside the glyph outline.

Sounds simple enough, but to make it work I had to write some scary code. :) And before you rush to write line segment information to file, you need to reduce their count for every block. I decided to save no more than eight line segments, and luckily, only a small amount of blocks have broken this limit. I reduced their number in two stages. First stage removed all horizontal segments, because they don’t have any influence on the result. Second stage removed line segments, starting from the smallest one and only if the following requirements are met: the starting and ending points are the ending and starting points of two segments, accordingly. Thus I could remove a segment without leaving any gaps.
A line segment is represented with four numbers. For the first GPU implementation I decided to write single line segment information into a single RGBA texel. One block data occupied a small 8 pixel row. If line segment count was less than 8, a segment (0;0)-(0;0) was saved to all redundant pixels. First shader without optimization was compiled to 120 ALU instructions, so to run it, I had to temporally choose ps_3_0 profile. Here is the code of this shader:
1st revisionIn the beginning of the shader you can see some strange manipulations with texture coordinates. The purpose of this is that for texture coordinates that point to a single line of 8 texels we need to get texture coordinates of the first texel in a group. We also get coordinates that show where we are in a block.
You can see that I used a different approach to define if pixel belongs to inside or outside parts of the outline. By default, we are outside the outline (white color, wind = 1.0), and with every intersection we multiply wind by -1.0; so we are changing white to black and vice versa. This is a bad decision; it is hard to optimize the chain of 8 dependent multiplications. I used it here, because I actually didn’t invent the normal approach at the time of writing. :)
More to that, we do not exploit the ability of GPU vector processors to process 4 float numbers simultaneously, and to fix this I had to change the data representation in texture. I had to write data in a way that you can get information of the one component of 4 line segments in one texture fetch. Line segment is represented using four numbers (x1; y1)-(x2; y2). I saved them in a slightly different order {x1; x2; y1; y2}, but this isn’t significant. In addition, a few operations were performed in preprocessing tool and vertex shader. Unfortunately, there is no vector division instruction; that could have saved me 6 instructions, which is a lot. Optimized shader compiles to 42 ALU instructions and runs in ps_2_0 profile.
2nd revisionIt's time to see the results!
Vector texture for Arial font resulted in 512x512 image, and only 55% of the space is used. Maybe I could have packed the glyphs tighter to reduce the size to 512x256. Image size is 1Mb and it can be compressed to 43kb using WinRAR. I haven’t tried to save the image into compressed dds, because the result will certainly be wrong.
Here is the render of vector image:

And close-up of one glyph.
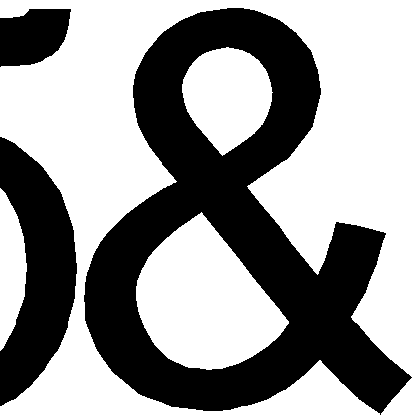
The method has some disadvantages:
There is no smoothing and the font looks bad when minified (following demo will show hand-made SSAA to smooth the image). Maybe it is possible to implement some smoothing inside a shader, but at the moment I don’t have any good ideas on how to do it.
There are only two colors (arbitrary, not only black and white).
My implementation shows vector textures that are used for font rendering, but it can be applied to any other two-color vector image.
Some people asked me to make a demo (My first GPU implementation was written as an effect for ATI Render Monkey), and here it is. You can download archive
here (109kb).
Move the plane by dragging the mouse or by pressing Arrow keys.
Zoom in and out using mouse wheel or +/- buttons.
'A' button will toggle improvised 8x supersampling (render is performed eight times with subpixel shifts and additive blending). Its impact on speed is as dramatic as the impact on quality:

You can also find source code for the render, but not for the preprocessing tool.
You do not need D3DX to run this demo.
On ATI 2600XT I get 640/92 fps (no SSAA/SSAA). I would like to see results on your hardware.
For further reading:
Hugues Hoppe,
Texel Programs For Random-Access Antialiased Vector Graphics.
 ,
,





